A Different Form of Data Management
The Concept of Linked Lists
To this point, you have been using arrays as your go-to data structure. Arrays are a good fall back in the sense that you can put pretty much any data, whether primitive or object, into an element, and find it later at the index at which you placed it. Simply put, arrays are pretty good tools, with maybe a couple of issues. The first one is that arrays are limited to the capacity given to them. You can make arrays with adjustable capacities but that takes quite a bit of overhead when transferring from the old array to the new one, and can become a big problem when there are a million, or a billion, elements in the array.
The linked list offers a little more flexibility. You can keep adding new data quantities for as long as you have available memory, which is essentially limitless with Operating Systems these days. Each data quantity, which we will now call a node instead of an element, is created at the point of storing the data, and then it is added to the list in a process called linking. Like an array element, a node can be added, appended, or inserted at any location in a linked list. This will be discussed in the next topic. The bottom line is that this is a new paradigm; you need to think about your data as linked nodes instead of a set of large indexed elements.
The Concept of Dynamic Memory Access
As mentioned, an array is something you create or instantiate prior to its use. This is considered to be statically defined, meaning it is created once and never changes as the data structure. Even when arrays are resized, the original array is not actually resized but instead a new array is created to replace the old one. In the case of linked lists, and other data structures you will work with later on, a node is created at the point of being used. This is considered dynamic memory allocation, or "on the fly" memory allocation that happens at the point in the code where it is requested. The first step in this process is to instantiate a node, shown here being assigned to a pointer. Here is an example from a previous topic, slightly modified.
// creation of C node
firstStudentPtr = ( StudentStruct *)malloc( sizeof( StudentStruct ) );
OR
// creation of C++ node
firstStudentPtr = new StudentClass();
There are a few things to discuss about this. Consider the following.
- the variable firstStudentPtr must be a pointer to the correct type, (e.g., ether StudentStruct or StudentClass) to be able to "point at" either the struct or object
- the way to create dynamic memory with a C struct uses malloc
- the way to create dynamic memory with a C++ class uses the keyword/operator new
- note that the default constructor is used with the C++ class but any class constructor can be used
- also note that structs can be used in C++ as well; they are considered a special case of a class where all the data is public
The firstStudentPtr variable was declared as follows.
StudentStruct *firstStudentPtr;
OR
StudentClass *firstStudentPtr;
It is critical for you to remember that any pointer declared as a given type can "point at" any object of that class type. So, as declared, firstStudentPtr can point at any StudentStruct or StudentClass node, as appropriate.
This will become very important very soon. As a result of this, to have a linked list, there must alwasy be a head pointer which will point at the first node in the list. The head reference will almost always be a member variable in whatever linked list class within which you are working. This means that somewhere in your linked list class, there will be the following code. Note that this might occur more than once depending on the actions your linked list is capable of. Since we always think of references as pointers to objects, you can think of the head reference this way.

Creating a head pointer is pretty straightforward, as shown here. Note that to limit redundancy, only one type of pointer will be demonstrated from here forward. However, as you can see, they are fundamentally the same.
StudentStruct *headRef // C declaration
StudentClass *headRef; // C++ declaration
Note that the data type could be any kind of struct or object. For purposes of the class part, the class type StudentClass is used.
In most cases, a head reference will be set to NULL when the object is first constructed, so it starts out its life this way.

The sideways 'T' will always be the way of representing NULL. NULL itself simply means the reference is pointing at a standard value that is NOT a struct or object, and the way this is implemented should be pretty obvious.
headRef = NULL;
It is very important that you recognize that pointer variables do not "hold" data like primitive variables do. Instead they "hold" the address of where an object is located in memory. A pointer is just an integer variable holding an address in memory.
So with that in mind, how do you start a linked list? Well, you create a node, put data in it, and assign the head reference to the node. An example was provided above with a generic reference. Here it is again being assigned to the head reference, and becoming the first node in the linked list.
// member data must be added later
headRef = (StudentStruct *)malloc( sizeof( StudentStruct ) );
// member data added in constructor
headRef = new StudentClass( "Susan Sarenvo", 246810, 'F' );
When malloc is used, the programmer must provide the exact number of bytes to be allocated from the operating system. The C language has a handy tool called sizeof which calculates exactly how many bytes are required by any given data type, including a struct, and this is presented here.
When new is used, the same calculation is also conducted, however it is automatically done by the C++ language so the programmer does not have to provide this information.
In this case, the initialization constructor for the StudentClass was used. The linked list would now look like the following.

Having come this far, you need a little background support.
The Node Itself
In this case the StudentStruct stores a name, student ID, and gender. Nodes can store one or more items that are considered the data of the given node. However, a linked list node must also have a "next" link that can point to the next node in the list, or to NULL if there is no subsequent node. Take a quick look at what a node is, or could be.
The C version is provided first.
typedef struct structStudent
{
char name[ STD_STR_LEN ];
int age;
double GPA;
long studentId;
struct structStudent *nextPtr;
} StudentStruct;
Next is the C++ version.
class StudentClass
{
public:
// constructors, methods, etc.
private:
// private methods, as needed
// private data
char *name;
int studentId;
char gender;
StudentClass *nextPtr;
};
Note that in both cases, some part of the program must initialize the nextPtr to NULL. This is done in the constructors for C++ but it must be handled elsewhere in the code for the C struct. Also consider the following.
- The first thing to note is that in both cases, these are stand alone nodes. Be aware that they can also be incorporated into other classes as internal or nested components
- The next thing to note is that there is usually some kind of initialization constructor and some kind of copy constructor for nodes. This is very common for nodes as that allows the data to be placed in the node at the same time the node is first instantiated, as you observed in the headPtr assignment earlier. And to add to a previous note, in C++, structs are special cases of classes and are allowed to have constructors
- The next thing to note is that, as mentioned previously, the node itself will always hold some form of data and some form of "next" link. In this case, the nextPtr variable is a pointer to type struct studentStruct (which becomes defined as a type StudentStruct) in C and StudentClass in C++ so it can refer to other nodes of its own kind
- The (almost) last thing to note, at this point, is that in the constructor, the nextRef link will always be set to NULL
- The last thing to note, is that for the struct, the actual name of the struct is structStudent so that is the data type that had to be used in the struct declaration of the next pointer. However, the typedef quantity, or alias, representing the struct is StudentStruct, so you can see where each is used in this initialization
This is just the beginning but these observations are important.
And Now, Let's Link
The first node has been added to the linked list. That was easy, it was just assigned to the head reference. However, once the head reference has been linked to the first node, it must always point to the first node no matter how far down the list you go. This is the only way to know where to find the list when you come back to access the data. Let's look at adding the next data item (node).
C first. Since C does not have constructors, all the data must be added individually.
headRef->nextPtr = (StudentStruct *)( malloc( sizeof( StudentStruct ) );
strcpy( firstStudent->nextPtr->name, "Roger Rolanda" );
firstStudent->nextPtr->age = 23;
firstStudent->nextPtr->GPA = 3.475;
firstStudent->nextPtr->studentId = 4357628;
firstStudent->nextPtr->nextPtr = NULL;
C++ next.
headRef->nextPtr = new StudentClass( "Roger Rolanda", 135792, 'M' );
That wasn't very hard. The linked list now looks like the following.

When the headPtr used the arrow operator to access the nextRef, which is a pointer to a StudentClass, it connected the second node to the first node. Remember from previous topics that the arrow pointer is how C and C++ "point" at dynamic data. Again note that every new node starts with its nextPtr pointing to NULL. This is done in the C++ constructor but must be done manually with the C struct. And now we have a linked list of two nodes.
Now comes the conundrum. It might seem like the next thing to do would be to assign the head references' next reference's next reference to the next item, as shown here.
// in C
headRef->nextRef->nextRef = (Student *)malloc( sizeof( Student ) );
strcpy( headRef->nextRef->nextRef->name, "Julie Jazamina" )
// in C++
headRef->nextRef->nextRef = new NodeClass( "Julie Jazamina" );
It should be noted that this does actually work. However, you can see where that would go. After the first thousand, or even hundred of these, your code would be, let's say, awkward at best, with all the nextPtr arrow operations. This has to be done differently. You know that you cannot change the head reference. It must always stay in position pointing at the first node. This calls for using another reference, like the following.
// In C
Student *wkgPtr = headPtr;
// In C++
StudentClass *wkgPtr = headPtr;
This variable is declared and assigned in the same statement but you should know that you could do this in two steps. But what has happened here? The wkgPtr pointer is now pointing at the same thing as the head pointer, shown here graphically.
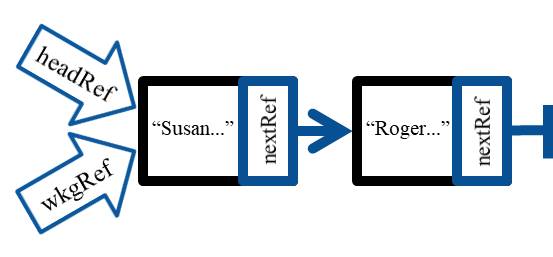
And how does that help us? Well, we cannot change the headPtr; it must always keep referring to the first node. However, we can change the wkgPtr, and it is easy to do, as you can see here.
// In C and C++
Student *wkgPtr = wkgPtr->nextPtr;
Here you are telling the working pointer to be assigned to the next node it is pointing at. Stop and think about this as needed. It is pointing to the first struct/object (i.e., the node), but you are asking it to now be assigned to the first node's next reference. It will now point at the next node, as shown here.
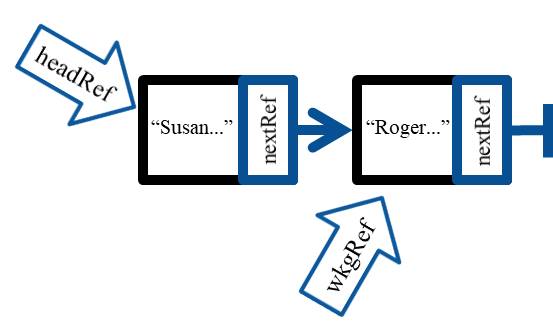
How's that for cool? Like any other pointer, the wkgPtr can refer to or point at any Student or StudentClass node so we now have a way to manage individual nodes across a list of any size. For example, we can write the following code.
// In C, noting that all the other data must added
wkgPtr->nextPtr = (StudentStruct *)malloc( sizeof( StudentStruct ) );
// In C++, with constructor
wkgPtr.nextPtr = new NodeClass( "Julie Jazamina" );
And we will get the following.
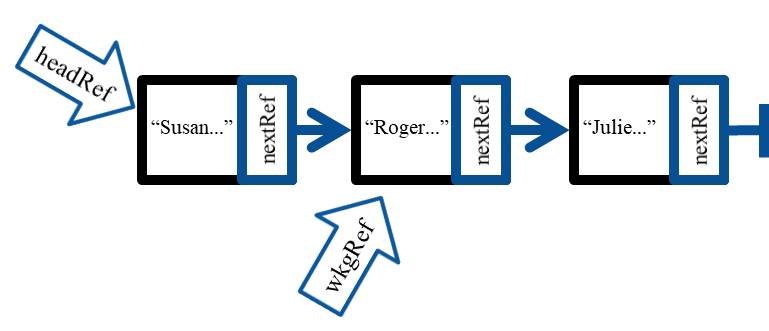
You should now see how you could use a loop to move wkgRef up to the next node, and then add another one, or sometimes just look at one to see if you can use the data stored there. There are no indices here, and there is only one way to access a linked list. That is to start with the head pointer, and then increment your working pointer across the list until you want to read or replace a node, search for one, or even insert or remove a node. Again, pretty cool.
Linked Lists, The Concept
This topic has supported your introduction to the concept of linked lists. In the next few topics, you will look at how to add and remove data from a linked list, and you will even view a couple of linked lists that don't look quite the same as this one. As always, there is only one way to learn how to program . . . and that is to program. As you are exposed to the different strategies for manipulating linked lists, you need to practice each and every one of them, multiple times. When you do this, you will find that thinking about linked lists is just as natural as thinking about arrays, you will be more comfortable and confident, and you will be able to develop your own linked lists. All good. Keep at it.